
"[1] Don't decay the learning rate, increase the batch size" 리뷰, 설명입니다.
Learning rate decay 라는 것을 들어보셨나요?
머신 러닝에서 굉장히 중요하고 민감한 learning rate라는 하이퍼 파라미터를, 학습이 진행됨에 따라 점차 줄이는 것입니다. 대부분의 머신 러닝 테크닉이 그렇듯이 learning rate decay를 해보니 generalization이 잘 되더라, 로 시작해서 이러이러해서 잘 되는 것 같다라고 설명합니다. "[2] On large-batch training for deep learning: Generalization gap and sharp minima"라는 논문에서 해답을 찾을 수 있습니다.
1. Generalization & Learning rate

Generalization이란 일반화입니다. 다시 말해 얼마나 모델이 본 적 없는 데이터에 대해 퍼포먼스가 좋냐? 입니다. 모델의 train set에 무한개의 데이터가 있으면 어떠한 입력에 대해서도 다 잘하겠지만 실제로 불가능한 일이고 학습 시간도 무한히 걸리겠죠. 때문에 머신 러닝에서는 어쩔 수 없이 train set과 test set의 데이터에 차이가 나고 분포(어떠한 것에 대해서든요, 밝기나 각도 등등) 자체도 다를 것입니다. 위 이미지를 보시면 x축이 어떠한 변수라고 하고 f(x)가 그에 대한 값입니다. 학습 단계에서는 training function만 보고 있는 것이죠.
training function과 testing function이 현재 미세하게 다른데, 위 이미지에서 flan minimum이 sharp minimum보다 안정적이죠? 머신 러닝 모델의 학습 과정에서는 loss 함수를 만드는 여러 개의 파라미터에 대해서 gradient descent를 통해 minimum을 찾는데, generalization을 위해서는 flat minimum을 찾는 게 좋다! 라는 것이죠.
그러면 learning rate와의 관계에 대해 보겠습니다.

learning rate가 크면 한 번의 기울기로 엄청 많이 이동하겠죠. 위 사진에서 Too high 가 안 좋아보이지만 필요할 수가 있습니다. 저 아래로 볼록한 함수가 하나가 아니라 local minima가 매우 많은 상황이죠. 그럴 때는 learning rate를 크게 잡아서 왕창왕창 점프 시키는 게 필요할 것입니다.
또한 결국에는 converge를 시켜야 하기 때문에 점차 learning rate를 낮춥니다. 이 뿐만이 아니라 앞서 말한 generalization 측면에서도 작은 learning rate가 좋습니다. Flat minima 을 잘 찾기 위해서는 작은 learning rate로 조금씩 조금씩 이동해가면서, 그 모든 곳에서 loss가 작게 나오는 곳이 flat 하다는 것이죠.
2. SGD에 대한 고찰
Stochastic Gradient Descent (SGD)은 모든 train dataset 중에서 랜덤하게(Stochastic) 일부만 뽑아(Batch) Loss에 대한 기울기(Gradient)를 계산하여 움직이는(Descent) 방식입니다. 반면 Gradient Descent(GD)는 모든 데이터 셋에 대해서 기울기를 계산해서 움직이죠. Batch size 또한 하이퍼 파라미터인데 배치 사이즈가 작으면 더 noisy 한 움직임을 보이겠죠? 트레인 데이터셋 전체로 기울기 계산하면 한 번만 이동하고 전체 경향을 잘 표현하지만 정말 극단적으로 배치 사이즈가 1이라서 하나씩만 보면 마구 튀면서 이동하겠죠.
[1] 논문에 따르면 scale of random fluctuation g를 계산했습니다. scale of random fluctuation, 다시 말해 얼마나 랜덤하게 왔다갔다하는지는 다음 식으로 표현됩니다.

m은 momentum(과거의 가던 방향대로 가는 가중치)이고 N은 train data set size, B는 배치 사이즈이고 엡실론이 learning rate입니다. 만약 m이 0이고 대부분의 경우 B보다 N이 매우 크므로 g를 다음과 같이 단순히 표현할 수 있습니다.

이 식에서 알 수 있는 점은 배치 사이즈를 키우는 건 러닝 레이트를 줄이는 거랑 동일한 효과를 나타낸다.라는 점입니다.
[1]논문에서는 다양한 태스크에 대해 실험해보았고 실제로 비슷한 로스 그래프, 퍼포먼스를 보여줍니다. 조금 더 자세히 실험 과정을 설명하자면, 만약 100 에포크마다 러닝 레이트를 반으로 줄이는 스케쥴이 있다면, 러닝 레이트를 가만히 두고 100 에포크마다 배치 사이즈를 두 배로 늘려 학습하는 것이죠.
그러면 둘이 같은 의미를 가지는데 그럼 왜 굳이 기존의 러닝 레이트를 줄이는 방식 대신에 배치 사이즈를 키우느냐??
GPU 메모리가 허락하는 내에서 배치 사이즈가 커지면 학습이 빨라집니다. parameter update 횟수가 줄어들기 때문입니다. 만약 트레인 셋이 1000이고 배치 사이즈가 100이면 10번의 파라미터 업데이트가 있지만 배치 사이즈가 1이라면 한 개 가지고 기울기 계산하고 업데이트하고 이 과정을 1000번 해야하기 때문입니다. 그래서 저 [1] 논문도 구글이 쓴건데 GPU 메모리는 하드웨어적으로 늘릴 수 있다. 라고 나와있더라고요. ㅋㅋ 구글은 가능하겠죠. 뭐 머신 러닝 분야가 그냥 최고의 하드웨어를 투입하는 분야니까 그럴 수 있다고 생각합니다.
저도 테스트를 해보았는데요, 그냥 단순히 MNIST classification 태스크를 시켰습니다. 자세한 코드는 제 깃허브에 있습니다. 링크에 [1]논문 외에도 4개의 논문에 대한 테스트가 있는데 추후에 작성하겠습니다.
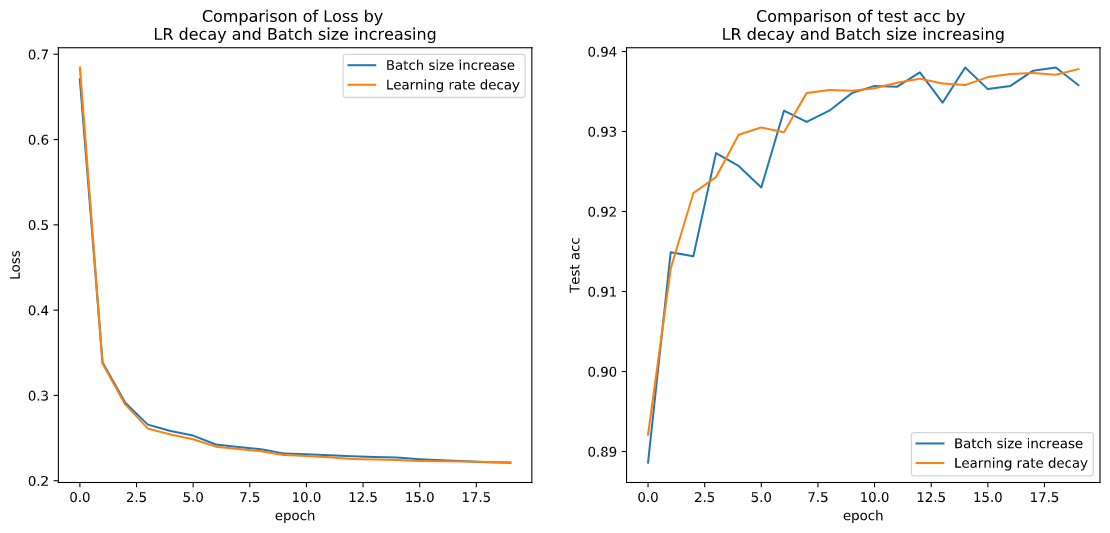
굉장히 유사한 그래프를 보여주어 저도 놀랐습니다.
사실 제 코드가 정말 대충되어 있을 것인데 lr decay는 pytorch에서 lr_scheduler가 기본으로 있어서 그걸 사용하면 되고 Batch size increase의 경우 저는 기준 epoch 이상이 될 때 dataloader를 새롭게 선언해주는 꼼수를 사용했습니다.
'파이썬 & 머신러닝' 카테고리의 다른 글
| [Pytorch] 진짜 커스텀 데이터셋 만들기, 몇 가지 팁 (16) | 2021.10.04 |
|---|---|
| [CUDA] GPU 메모리는 할당되어 있는데 프로세스가 안 나올때 (3) | 2021.05.04 |
| 최근 머신 러닝 핫한 연구 분야 (2/3) (0) | 2020.12.20 |
| 최근 머신 러닝 핫한 연구 분야 (1/3) (0) | 2020.12.14 |
| FNN, CNN, RNN 장단점 (0) | 2020.05.19 |
| [torchsummary] Pytorch에서 keras처럼 모델 출력하기 (0) | 2020.05.06 |
| [Pytorch] 모델 '적절하게' 저장하기 (+ 여러 모델) (0) | 2020.04.15 |
| [Pytorch] Dataloader 다양하게 사용하기 (custom loader) (2) | 2020.04.15 |
